
專案概述與核心痛點
台灣金融法規 AI 問答網站:涵蓋 26 部台灣金融法規,共 2,695 條條文( 網站可 👈)
台灣金融法規是公開的,但找起來很痛苦。26 部法規、2,695 條條文散布在全國法規資料庫,格式不一、交叉引用,查一個跨法規的合規問題往往要開十幾個分頁逐條比對。
直接套 LLM 也行不通——金融法規場景的核心需求是 可溯源:答案必須來自哪條哪款,因為它要對外交代、要承擔法律責任。LLM 擅長說得有說服力,不擅長說得有根據。
策略思考
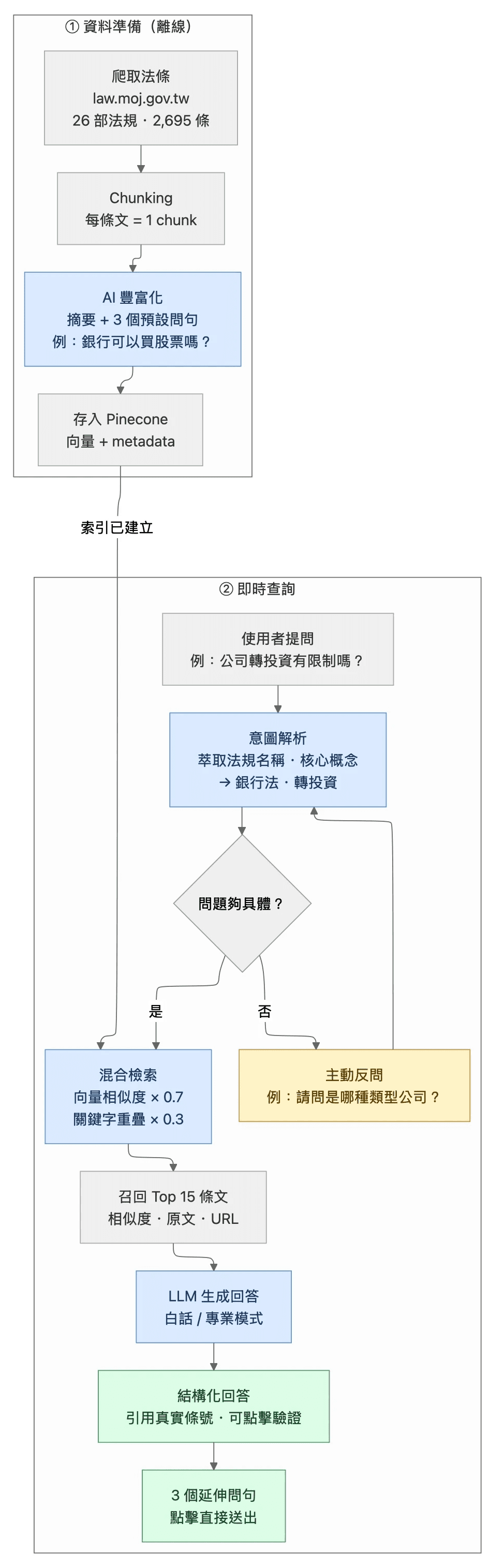
本產品以 Vibe Coding 方式推進,以 Claude Plan Mode 為協作核心,先把每一層架構決策討論清楚,再逐步實作。
資料端:替每條法律「預先想好別人怎麼問它」
很多法條的主詞根本不在自己身上。「違反前項規定者,處以罰鍰」這種條文,脫離上下文後幾乎是空殼 —— 使用者搜「罰款」或「違規處罰」,向量搜尋根本對不上。
解法是在 chunking 階段,替每一條條文用 AI 預先生成兩樣東西:一段摘要(交代這條在講什麼),以及三個真實使用者可能怎麼問的自然語言問句。以銀行法第 74 條為例:
原文:「商業銀行得投資有價證券……投資總額不得超過該銀行實收資本總額之百分之二十五。」
AI 預生成問句:「銀行可以買股票嗎?」「銀行投資有上限嗎?」「銀行持股比例限制是多少?」
使用者用任何一種說法提問,系統都能命中這條。這樣即使原始法條語意模糊,也早已備好多種被找到的路徑。

這個做法借鑑了 HyDE(Hypothetical Document Embeddings,假設性文件嵌入) 的精神 —— 預先生成「假設使用者會怎麼問」,讓真實提問能比對到預期問句,而非直接比對生硬的法條原文。
查詢端:先讀懂問題,再決定搜什麼
使用者送出問題後,系統不是直接丟進向量資料庫搜尋,而是先用 LLM 做一輪意圖解析——從提問中萃取出「涉及哪部法規」「核心概念是什麼」「有沒有提到具體條號」。例如使用者問「公司轉投資有沒有比例限制」,系統會先辨識出這是銀行法範圍、關鍵詞是「轉投資」與「比例」,才縮窄範圍送出精準檢索,而不是把 2,695 條全部掃過一遍。
問題太模糊時(例如只輸入「洗錢」兩個字),系統會主動發出反問,釐清具體場景後再檢索,避免不相關內容污染 LLM 的回答脈絡。
這套架構預留了擴充空間:法條是骨架,函釋與官方 FAQ 是血肉。下一階段將主管機關函釋納入同一知識庫,讓系統不只能引用規定,也能提供官方情境詮釋。
解決方案亮點
讓語意模糊的法條也能被問
每條條文進資料庫前,AI 會預先替它生成三個「一般人可能怎麼問這條法規」的自然語言問句,存為 metadata。使用者不管用哪種說法提問,都能命中正確條文,不依賴使用者自己知道正確術語。
引用必須是真實存在的條號
回答生成前,系統已先把來源卡片(條號、相似度分數、原文片段、法務部政府網站連結)送出給使用者。Prompt 層明確禁止 LLM 使用「依第 X 條」類佔位符——每個引用都對應資料庫中真實存在的條文,可點擊、可比對、可追溯。
兩種模式,服務不同受眾
同一組檢索結果,白話模式把法律術語翻譯成日常語言給一般使用者;專業模式輸出標準法務引用格式供法遵人員直接使用。切換說話方式,不換底層資料。
專案成效與商業影響
查詢門檻從「需要專業背景」降到「會打字就行」
業務端或法遵人員直接用口語提問,幾秒內完成跨 2,695 條條文的檢索,取得結構化回答,不再依賴人工比對。
把信任 AI 這件事變得有憑有據
每次回答附帶可驗證的來源連結,使用者不需要相信系統,只需要點進去確認。工具定位從「輔助參考」升格為「可對外出示的查詢紀錄」,符合金融業對資訊可追溯性的基本要求。