RAG|Graph RAG|AI|POC by Vibe Coding( Claude Code )
專案說明
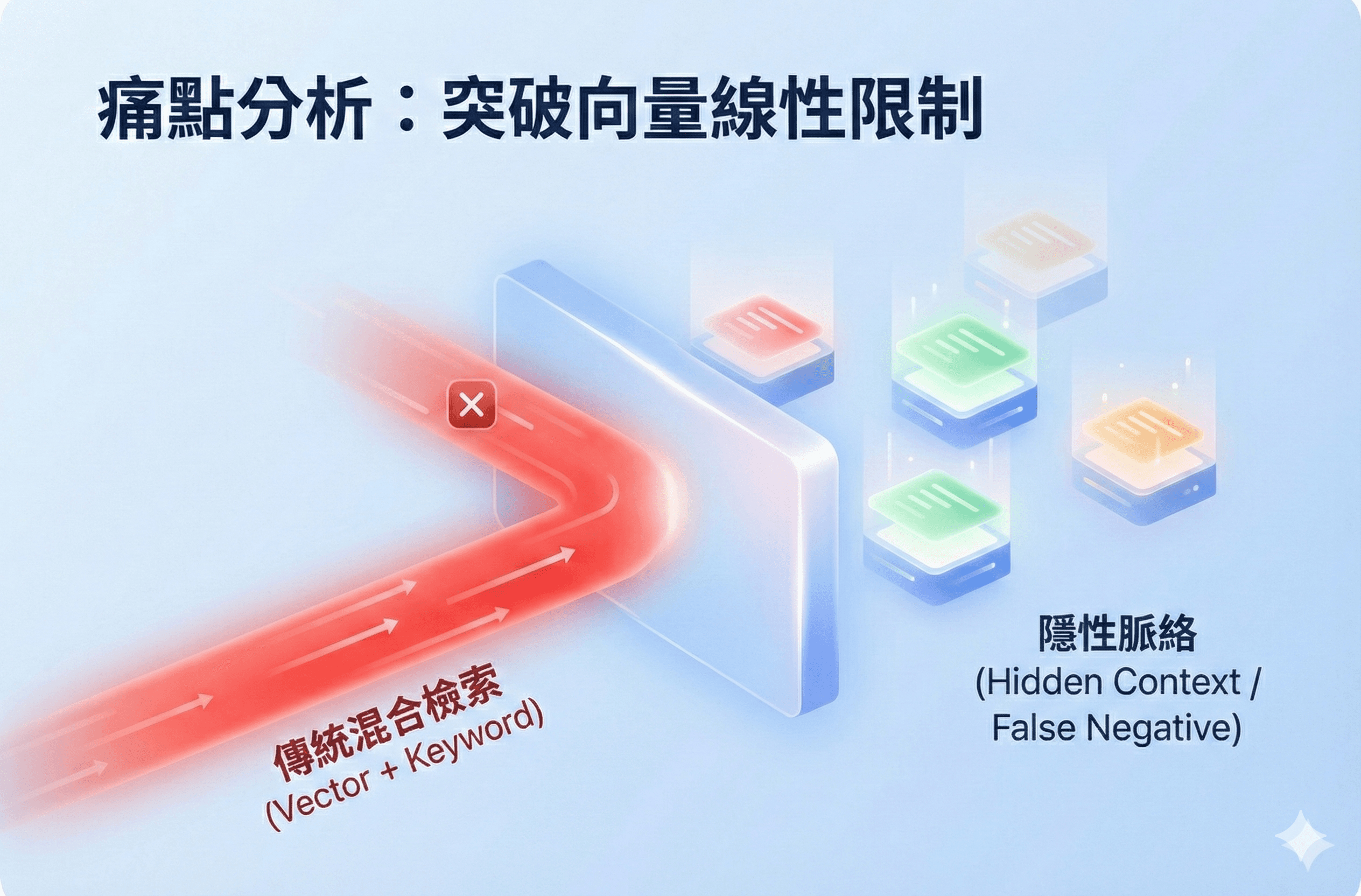
GraphRAG 知識圖譜檢索 POC 是一項為了突破現有 RAG 召回率瓶頸 所發起的技術驗證專案。
由於產品既有的「關鍵字 + 向量」混合檢索高度依賴餘弦相似度,在處理企業內部繁雜文件時,經常無法有效召回「邏輯緊密但字面/向量距離較遠」的關鍵段落(False Negative)。
為解決此痛點,本專案引入 GraphRAG(圖譜增強檢索),旨在驗證透過 Neo4j 建構知識圖譜,能否利用「實體關係」補充傳統檢索的不足,抓取文件中的隱性脈絡,以滿足客戶端對於高精準度問答的嚴苛要求。
專案背景
在現有的 AI Search 產品線中,我們主要採用「關鍵字 + 向量」的混合檢索模式。然而,在面對客戶端內容繁雜的技術文件或稽核規範時,我們發現 單純的餘弦相似度(Cosine Similarity)存在顯著侷限:高相似度往往不代表高相關性(False Positive),導致真正具備邏輯關聯的參考段落被排擠,無法被召回。
面對客戶對「召回率(Recall)」日益嚴苛的要求,我們面臨的挑戰是如何突破向量檢索的線性限制,讓系統能夠像人類專家一樣,順藤摸瓜地找出「跨段落」但「邏輯緊密」的知識點,進而提升最終生成的答案品質。
專案階段
階段一:痛點分析與技術選型
分析現有混合檢索在複雜文件場景的召回瓶頸,定調引入 GraphRAG 技術路徑
階段二:Vibe Coding 快速原型開發
採用 AI 輔助編碼(Vibe Coding)模式,快速搭建包含文件解析、實體抽取至圖譜視覺化的完整 POC 架構
階段三:技術可行性驗證
驗證「圖譜關聯檢索 -> 回溯原始段落 -> 生成答案」閉環的有效性,完成定性評估
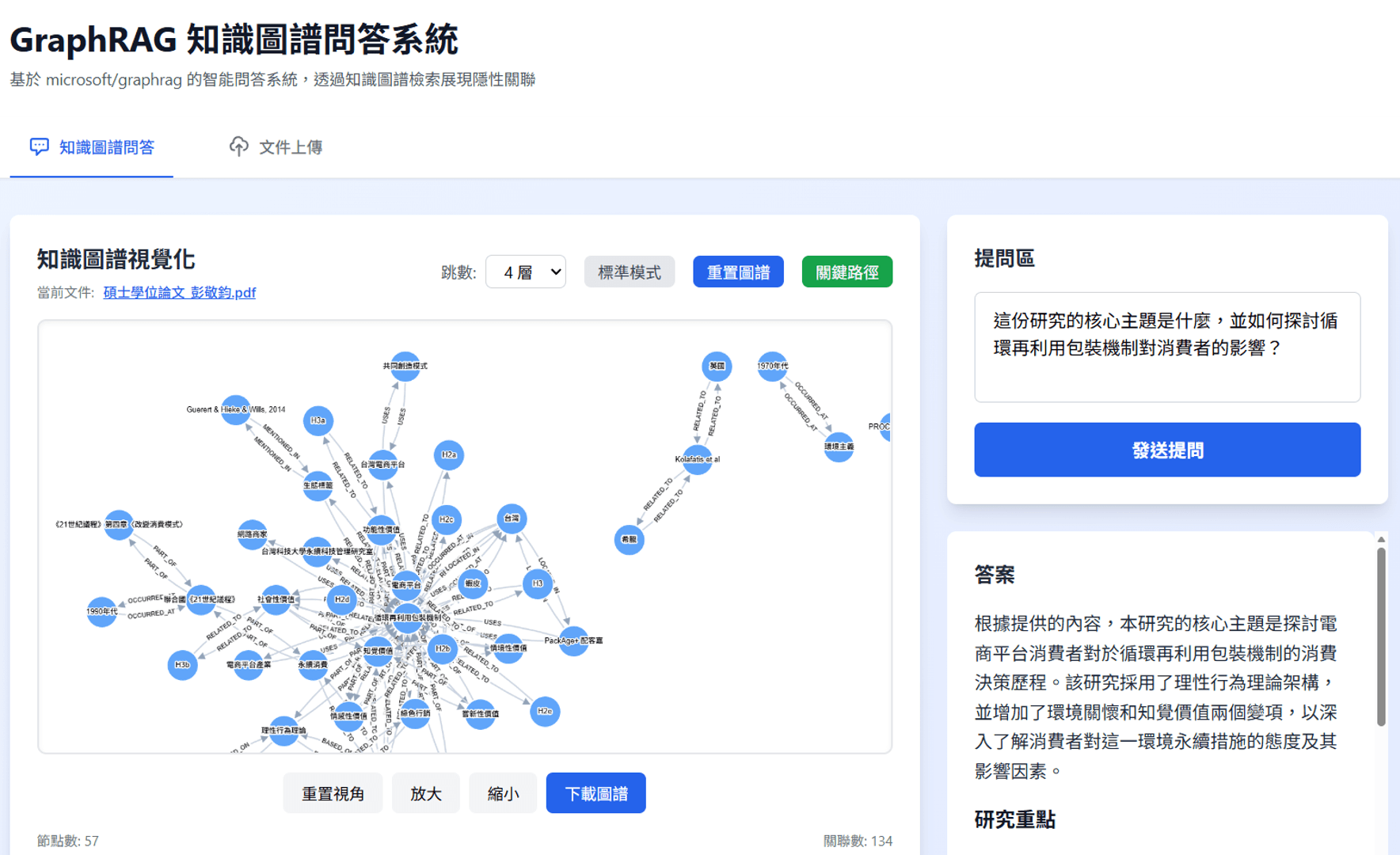
專案過程
採用 Vibe Coding 模式,加速技術驗證週期
為了在資源受限的情況下快速驗證 GraphRAG 的價值,我採用 Vibe Coding 策略進行開發。
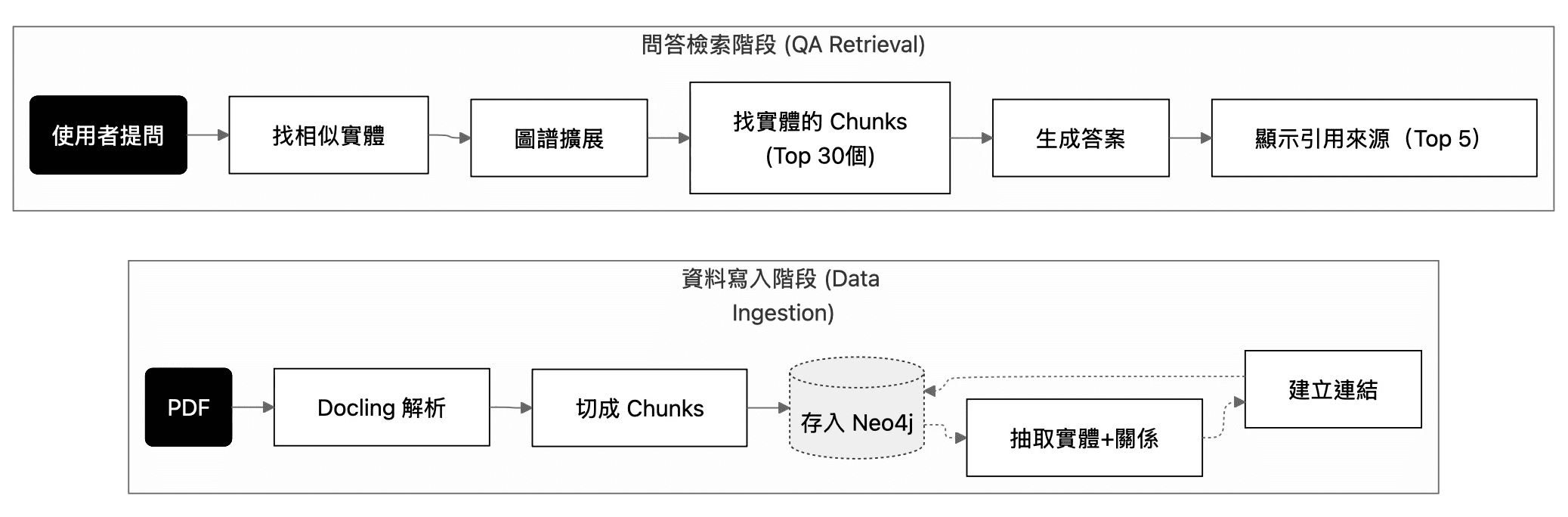
利用 LLM 輔助 Docling 解析 API 串接、Neo4j Cypher 查詢語句與 React 前端視覺化邏輯,在極短時間內( 1 週 )完成了從資料庫 schema 設計到前端互動的原型搭建,證明了 PM 具備快速驗證深層技術假設的能力。建構自動化知識圖譜流水線(Data Ingestion Pipeline)
經 Claude Code Plan mode 協作,規劃自動化的 ETL 流程:
解析與分塊:
使用 Docling API 進行高精度 PDF 解析,並設定 1000 tokens 的 Chunk Size( 100 tokens chunk overlap )以保留充足上下文。
實體與關係抽取:
利用 LLM 並行處理進行實體(Entity)與關係(Relationship)的抽取,並透過 Embedding 模型(text-embedding-3-small)將非結構化文本轉化為向量,存入 Neo4j 圖資料庫,建立
MENTIONED_IN與RELATES_TO的關聯索引。
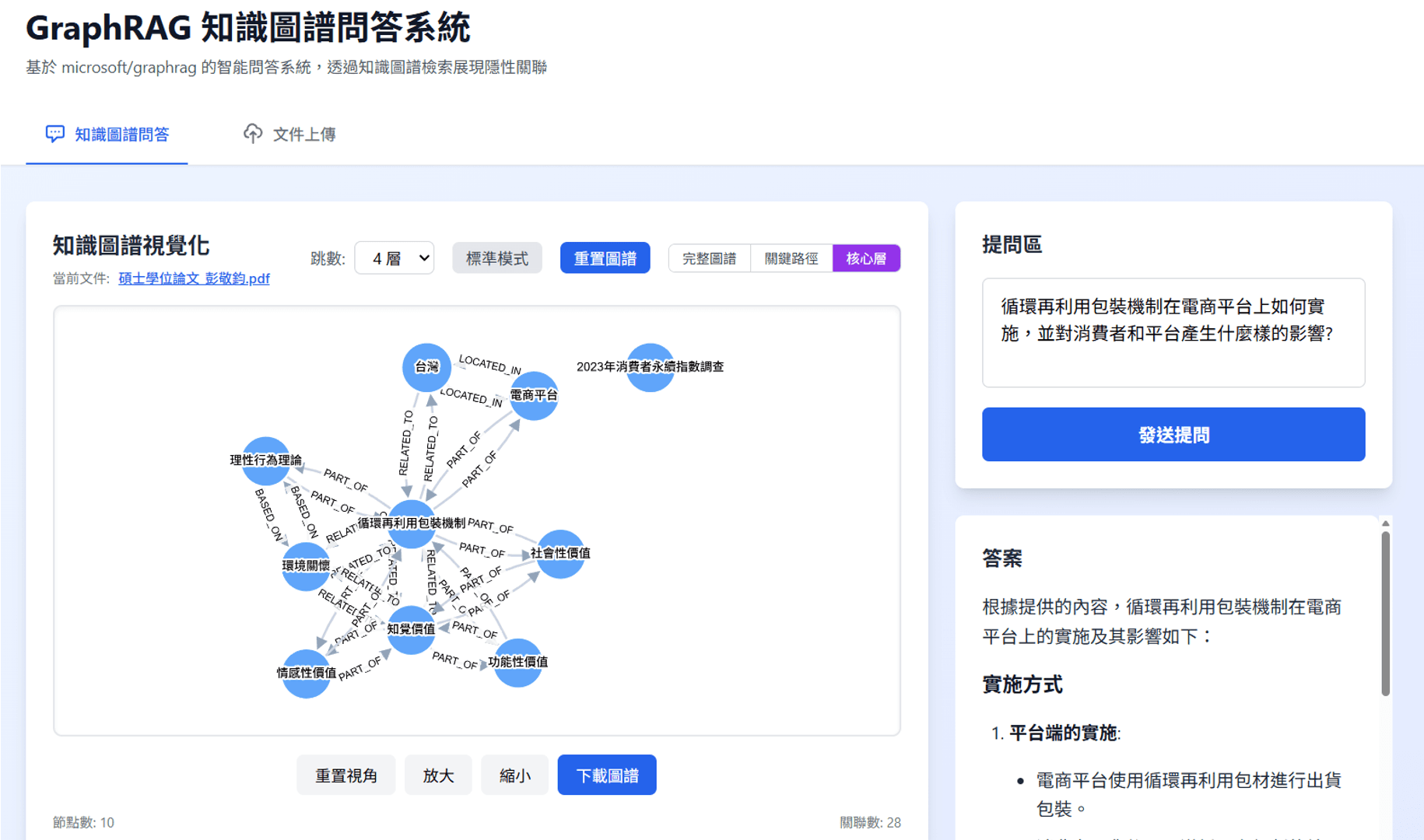
設計 N-Hop 圖譜擴展檢索邏輯
在檢索端,我捨棄了單純的關鍵字+向量混合搜尋,轉而使用了一套複合檢索邏輯
首先對使用者提問進行實體提取與向量搜尋,鎖定圖譜中的錨點( Nodes )
接著執行 N-Hop(多跳)圖譜擴展(預設 2-4 Hop),抓取與錨點具備強關聯的周邊節點
最後透過
MENTIONED_IN關係反向回溯至原始的 Source Chunks,選取 Top 30 關聯段落作為 LLM 的生成素材
驗證「圖譜 -> 文本 -> 生成」的有效性
POC 重點在於驗證路徑的連通性。我們成功打通了從「使用者自然語言提問」觸發圖譜遍歷,再精準定位回原始文檔段落的完整路徑。
特別是在處理隱性關聯問題時,驗證了系統能透過「A 關聯 B,B 關聯 C」的路徑,成功召回傳統向量檢索可能遺漏的 C 段落( 純向量餘弦相似度低 )
解決方案
實現「類人腦的關聯式檢索體驗」
核心策略:導入 GraphRAG 混合檢索,模擬人類專家的「聯想式」思考路徑
執行細節:突破傳統搜尋只能比對「字面相似」的限制,系統能進一步進行 N-Hop 深度推理( 例如:查 A 公司能自動聯想到其子公司 B 的財報 ),主動挖掘跨文件的隱性關聯
價值:解決使用者在複雜業務場景下「查不到完整全貌」的痛點,顯著提升 對複雜問題的回應深度與完整性
建立「有憑有據的知識索引機制」
核心策略:實體導向的精準索引與資料治理
執行細節:在資料處理階段,將抽象的「專有名詞(實體)」與具體的「原始文件段落(Chunk)」建立強綁定關係,確保每一個知識點都能精準回溯到原始出處
價值:大幅降低 AI 幻覺風險,確保產品提供的每一個答案都有憑有據,滿足企業客戶對資訊正確性的零容忍需求
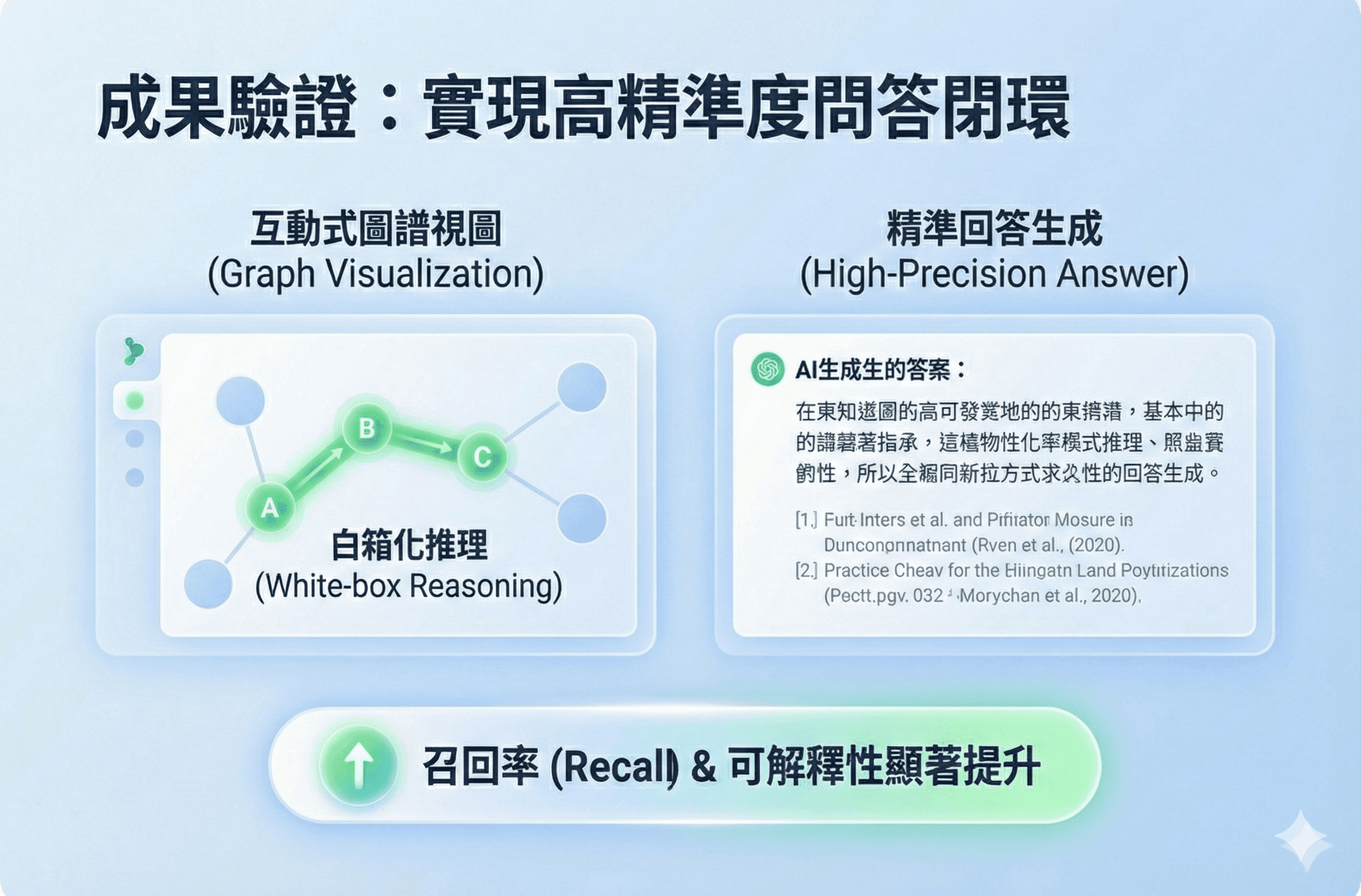
打造「白箱化的推理視覺化介面」
核心策略:基於 Cytoscape.js 的可解釋性 AI(XAI)互動介面
執行細節:將 AI 複雜的推理路徑轉化為直觀的「知識地圖」。使用者可切換查看「完整關聯」或聚焦於「答案生成的關鍵路徑」,一目了然 AI 是如何推導出結論的
價值:消除使用者對「AI 黑箱作業」的不信任感。透過視覺化呈現推理邏輯,讓使用者「看得到、懂得了、信得過」,顯著提升產品的易用性與信賴度


成果說明
突破複雜場景的檢索天花板
透過 POC 驗證,證明 GraphRAG 能有效解決傳統檢索在「跨段落推理」場景下的失效問題。對於法規稽核、技術維修等需要高度邏輯關聯的領域,成功驗證了從「單點搜尋」進化到「全面知識整合」的產品可行性
確立「高召回、高精準」的產品護城河
定性測試顯示,新架構能成功召回過去因「關鍵字不匹配」而被遺漏的高價值資訊。這確立了產品在企業知識管理市場的差異化優勢——不僅能回答「是什麼(What)」,更能透過關聯檢索回答「為什麼(Why)」與「如何(How)」。
極大化產品迭代與驗證效率
利用 Vibe Coding 模式,PM 獨立完成了從後端邏輯到前端視覺化的全端原型驗證。這不僅節省了昂貴的工程開發資源,更將「概念到驗證(Concept to Validation)」的週期縮短至極致( 本專案耗時僅 1 週 ),為團隊提供了具體且低風險的開發藍圖。