RAG|HYBRID RAG|AI|AI EVAL|產品管理 | 產品營運
專案說明
AI Search for KM 產品路線 — 讓企業知識庫從「有料但問不準」到「可控、可信、可量測」
AI Search for KM 是意藍資訊自研的企業級知識管理中台,透過 RAG(讓 AI 在回答前先去知識庫查資料,而非憑空生成)與 Tool Calling(讓 AI 依需求自動呼叫外部工具或資料庫)整合文件、資料庫與外部網頁,目標是建構「可控、可信」的企業知識搜尋體驗。
接任 PM 後,我面對到兩個產品核心痛點:
痛點一:AI 在說謊,但你看不出來
當系統找到的參考資料品質不夠好時,部分地端模型仍會「自行腦補」填補知識空白,給出聽似合理卻無所本的回答 —— 這種「幻覺」在企業決策場景中是直接的風險。
痛點二:知識庫有料,但使用者問不出來
經日誌統計發現,即便是有使用經驗的導入顧問,能成功取得有效答案的比率也只有 68% —— 知識的價值因為提問隱性門檻而面臨大量流失的問題
專案過程
「感覺不準」無法驅動優化,必須先讓問題數字化。產品演進分三個階段推進:
階段一:現況盤點與問題定義
接手產品後,系統性梳理產品現況:AI 回答品質靠人工感知、無客觀指標可依;使用者提問成功率從未被量測過。這個階段的核心工作是把「感覺不準用、不好用」轉化為可被追蹤的具體問題,為後續評測體系的建立確立方向。
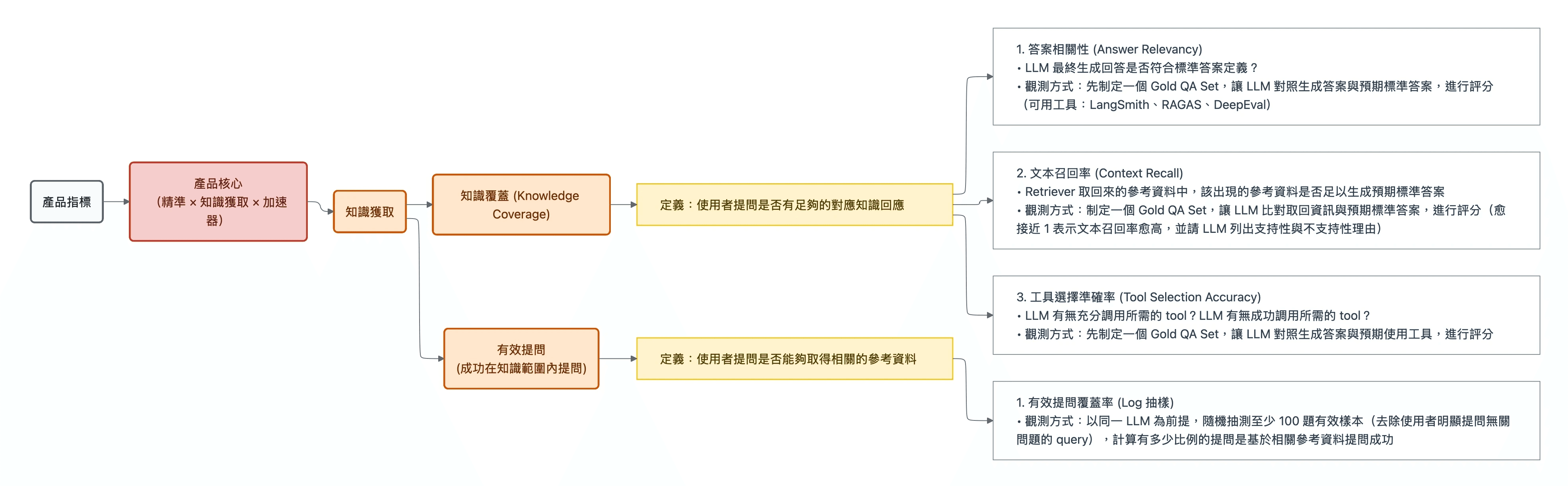
階段二:建立四維度評測體系
將「產品成功」拆解為四個可觀測的維度:
前線 / 客戶指標( eg. 品質可控( 使用者問答體驗 )、導入容易 )
知識獲取( eg. 知識覆蓋 × 有效提問 )
精準( eg. 文本有效召回、忠實度 )
效率提升( eg. 首 token 延遲 - TTFT )
階段三:指標驅動迭代優先級
例如:透過 AI Eval( 用 AI 自動替 AI 的回答打分數,解決過去仰賴人工抽樣的瓶頸 )發現隱患:
某地端模型在 Retriever 取回資料品質不足時,答案相關性( Answer Relevancy )看起來正常,但忠實度( Faithfulness ) 大幅下滑 —— 代表它在自行填補內容。這個問題若非靠系統性指標追蹤,幾乎無法被主觀感知察覺,且極其重要。

解決方案
RAG 指標體系 —— 全流程可觀測
覆蓋 Data Ingestion 到 Generation 的完整評測鏈,讓每個環節的品質都有數字依據。搭配 AI Eval 自動化執行,從「以前線回報客戶議題為主」升級為「持續性客觀監控」,讓迭代方向不再主觀拍板。
Rule-Based 邏輯護欄 —— 後端防禦線
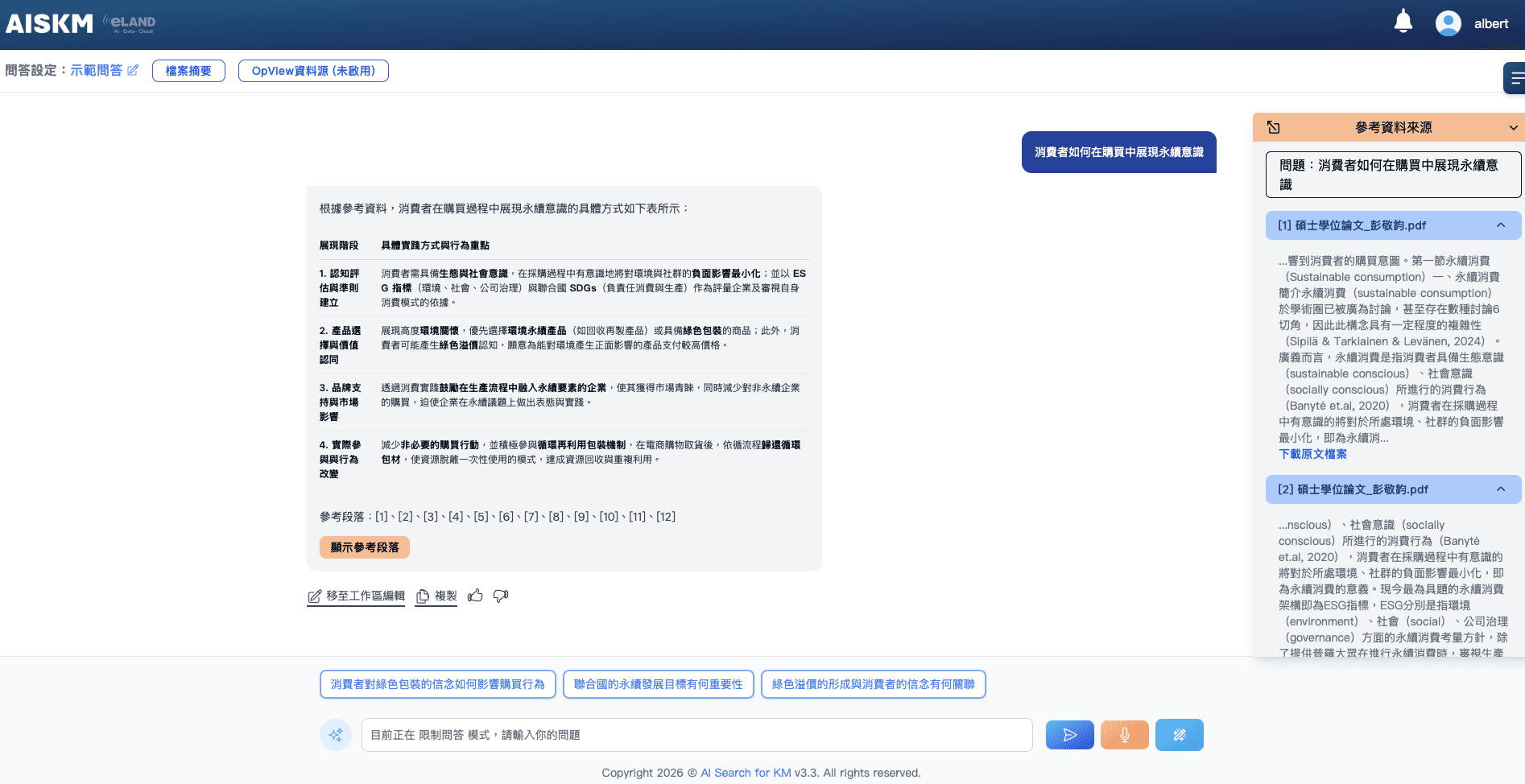
在 AI 生成答案之前強制設下門檻:系統搜尋到的最相關參考資料(Top_K=1)相關度分數須達 40 分以上,才會進入生成流程;未達標則直接回應「找不到足夠可信的參考資料」。同時兼顧資安防線設計,確保知識存取的合規邊界。
白話說:寧可承認不知道,也不要說謊說得很好聽。
建置「有效提問飛輪」產品規格
有效提問覆蓋率只有 68% 的根本原因有兩個:知識庫有盲點、使用者不知道怎麼問。因此將「有效提問 ✕ 知識覆蓋 = 知識理解 」視為產品標準規格,確保高機率「成功從參考段落取得關聯知識」:
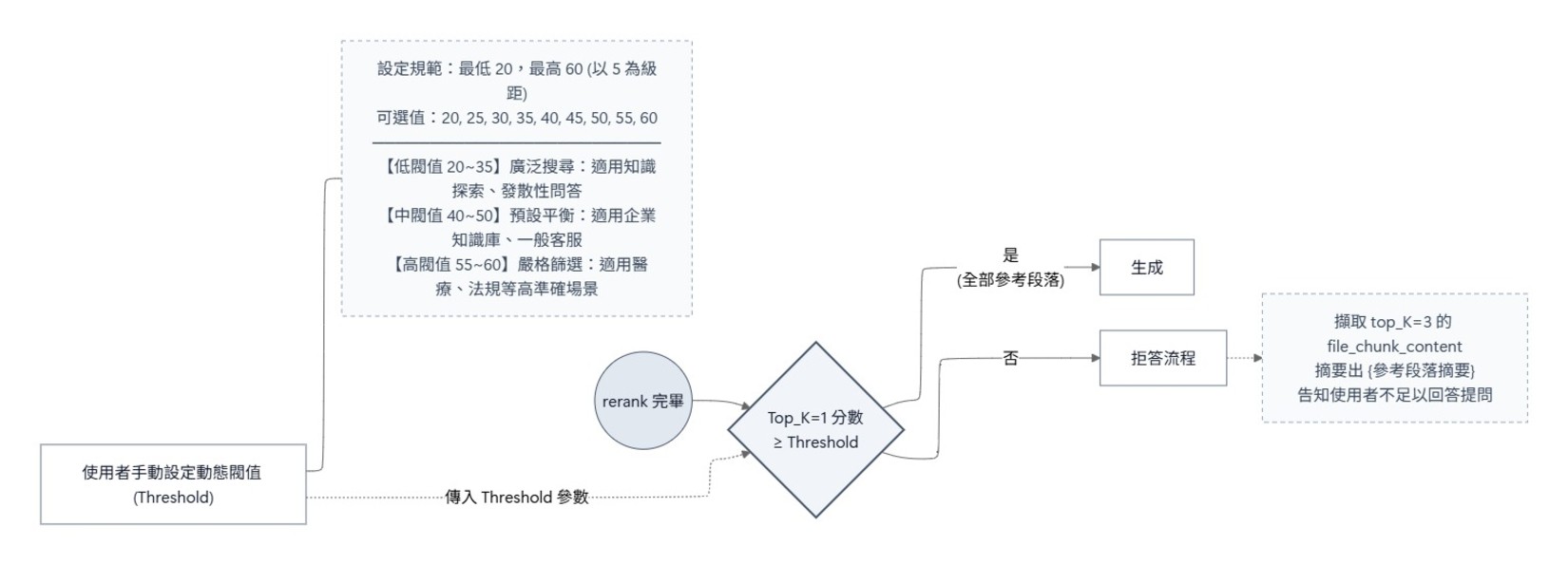
針對知識管理者:K-means 知識健檢
K-means 是一種自動分群演算法。知識健檢的邏輯是:將知識庫裡所有的文件內容向量化後,以使用者提問進行 K-means 提問類型分群,並以分群所取得的平均檢索資料相關度,提供知識管理者進行知識庫迭代時的參考
運作機制:
若「分群平均檢索資料相關度 < 40 -> 建議知識管理者該類型『 嚴重缺漏,急需新增文本 』」
若「分群平均檢索資料相關度 40 - 60 -> 建議知識管理者該類型『 品質尚可,建議優化細節 』」
若「分群平均檢索資料相關度 > 60 -> 建議知識管理者該類型『 知識覆蓋完整,請繼續保持 』」
針對一般使用者:動態生成問答引導建議
這個機制的關鍵在於「動態」與「基於取回段落」:系統在 Retriever 取回相關知識段落後,根據這些段落的實際內容即時生成建議問題。
換句話說,推薦的問題是從知識庫「長出來的」,而不是人工預設的——使用者照著問,Retriever 必然能找到對應資料,答案自然有所本。
相較於使用者隨意提問碰運氣,這些 建議問題大幅提高了「問對 → 找到 → 答對」的整體命中率,讓「小白用戶」也能順暢使用。



成果說明
透過指標體系的落地與對應產品迭代,專案取得了顯著的量化成果:
知識獲取能力突破性成長( 68% → 85%+ )
有效提問覆蓋率:從初期的低於 65% 大幅提升至 85% 以上。
成效歸因:透過「有效提問飛輪」的常駐引導,使用者不再需要猜測關鍵字。AB Test 後的指標成長,驗證了飛輪規格對提升互動品質的直接貢獻。
消除「隱性幻覺」,確保知識忠實度
忠實度提升:透過 Rule-Based 相關度閾值攔截機制,成功阻斷了地端模型在低資源情境下的「自行創作」行為。
風險收斂:在 Gold QA Set 測試中,模型的 Faithfulness(忠實度) 分數顯著提升,滿足了企業客戶對知識正確性的嚴格要求。
產品迭代效率大幅優化
決策效率:建立指標體系後,團隊不再依賴主觀猜測。需求收斂至規格確認的週期縮短,成功將產品轉向「指標驅動(Metric-Driven)」的高效迭代模式。