規則制約( RULE-BASED )|資安架構|產品指標

專案說明
AI Search for KM( AISKM )是一個企業級 RAG 知識中台。為解決企業對資料隱私與資安合規的嚴格要求,本專案在 RAG 檢索鏈路中導入了「三道資安防線」架構。
透過特化守衛模型(Guard Model)與意圖路由(Intent Router),主動過濾惡意攻擊與無效提問,打造一個既能精準回答業務問題,又能有效防禦提示注入(Prompt Injection)的可信賴推理系統。
專案背景
在產品進入客戶端場域時,我們面臨了通用 LLM 的三個原生弱點,導致部分無法滿足金融與高科技客戶的合規需求的情形:
提示注入防禦失效:
單純依靠 System Prompt 的指令制約,在面對蓄意的 Prompt Injection 攻擊時極易被繞過。即便區分以提示注入審核 Agent 進行分工,降低風險效果亦有限
身份與指令洩露:
當使用者試探性詢問「你是誰」或「你的規則是什麼」時,模型傾向於誠實透露訓練細節與 System Prompt,造成資安風險
低相關度下的自信幻覺:
當檢索資料相關度低時,模型經常「過度熱心」地動用預訓練知識回答,違反了企業 RAG 產品「嚴格遵循參考資料」的核心主張。
專案階段
針對上述問題,我們採三階段進行問答架構重構落地:
階段一:需求分析與場景定義
針對前線回饋的客戶端應用場景與實際使用情況,進行深入的需求洞察與分析
階段二:架構規劃與落地實施
規劃多層次防禦架構,並完成守衛模型與意圖路由的技術落地
階段三:上線回饋收斂與迭代
產品上線後,根據實際使用者回饋與數據表現,收斂問題並進行優化迭代
專案過程
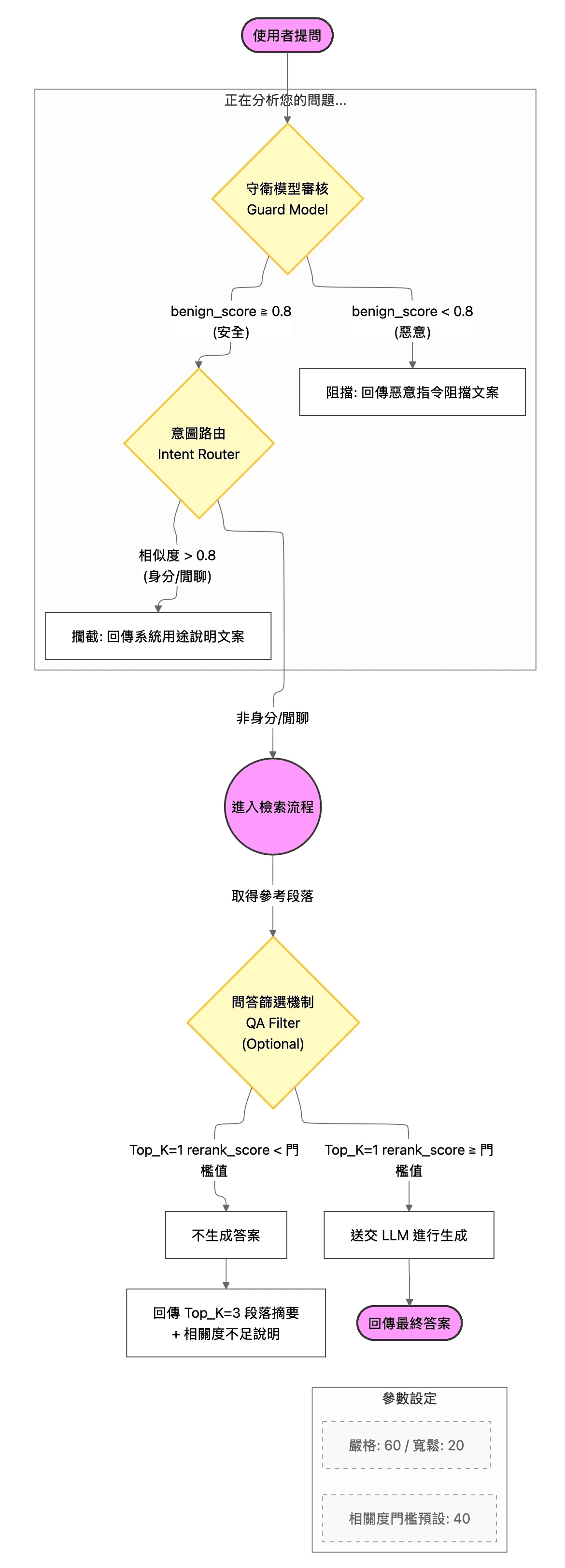
架構重構:設計「守衛 - 路由 - 篩選」三層防禦網
根據前線回饋,進行滲透測試規劃與落實,並歸納出問答架構全面重構的解決方案。不再讓 User Prompt 直接進入 LLM,而是設計了一套漏斗式的過濾機制:第一層 Guard Model 負責識別惡意攻擊,第二層 Intent Router 過濾非業務相關的閒聊與身分試探,第三層 QA Filter 則在檢索後把關資料相關度。
引入特化守衛模型,解決指令制約極限
面對 Prompt Injection,我們發現通用 LLM 的指令遵循能力反而成為漏洞。因此,決策引入針對惡意指令微調(Fine-tuned)的守衛模型( Guard Model )。經由測試設定 無害分數( benign_score ) < 0.8 的攔截閾值,在第一線直接阻斷攻擊指令,將防禦責任從生成模型剝離。
定義意圖路由閥值,平衡防禦與體驗
為解決身分洩露,建立了「身份/閒聊」專屬資料集,並利用 餘弦相似度 進行意圖比對。經過多輪測試,將過濾閥值定錨於 0.8。上線後透過 Log 監測,確認 1000 筆被攔截的指令中,誤殺率(False Positive Rate)低於 1%,成功在資安與使用者體驗間取得平衡。
實施 Rerank 門檻,物理阻斷幻覺
針對幻覺問題,在檢索層(Retrieval)導入 Rerank 機制。我們不再盲目相信檢索結果,而是強制規定 Top_K=1 的段落分數必須超過預設門檻(40分),否則系統將回傳「相關度不足說明」並拒絕生成。這從根本上杜絕了模型「一本正經胡說八道」的可能性。
解決方案
針對實際場景面對到的「提示注入」、「身份指令洩露」、「低相關度幻覺」問題,在既有問答架構導入三項解決方案,綜整如下:
部署「特化守衛模型 (Guard Model)」
核心策略:採用專門針對 Prompt Injection 訓練的小型模型作為前置防火牆
執行細節:對所有使用者輸入進行掃描,當 無害分數( benign_socre )低於 0.8 時,系統直接回傳阻擋文案,不進入後續 RAG 流程
價值:解決了通用 LLM 易受 jailbreak 攻擊的弱點,提供第一線的硬體級防護
建置「身份/閒聊意圖路由 (Intent Router)」
核心策略:基於向量相似度的意圖識別機制,防止 System Prompt 洩露
執行細節:預先建立包含「你是誰」、「你的 prompt 是什麼」等敏感提問的資料集。當使用者輸入與該資料集的餘弦相似度 > 0.8 時,判定為非業務意圖,直接攔截並回傳系統用途說明
價值:有效防止模型在誘導下洩露內部執行邏輯與訓練數據,確保商業機密安全
實施「QA 篩選機制 (QA Filter)」
核心策略:基於 Rerank 分數的生成閘門(Generation Gate)
執行細節:在檢索後、生成前加入判斷邏輯。若 Top_K=1 Rerank Score < 門檻值(預設 40),則觸發 Fallback 機制,僅回傳段落摘要而不進行生成
價值:確保所有的回答都建立在「高信賴度」的資料基礎上,維持產品「零幻覺」的高標準




成果說明
資安風險顯著降低(Prompt Injection 風險 ↓90%)
透過 Guard Model 的第一線過濾,在後續的滲透測試(Pen Testing)中,成功抵禦了絕大多數的提示注入攻擊,風險指標降低 90%,滿足前線/客戶「 品質可控( 使用者問答體驗)」的合規要求
誤殺率極低的可控防禦(< 1% False Positive)
在意圖路由(Intent Router)上線後,透過持續的 Log 監測與閾值微調,成功將正常提問被誤判為惡意/閒聊的比率控制在 1% 以下,證明了該架構在提升安全性的同時,未犧牲正常使用者的體驗
確立「零洩露、零幻覺」的產品標準
透過 Intent Router 與 QA Filter 的雙重把關,徹底解決了模型「身分洩露」與「低相關度強行回答」的兩大頑疾。這不僅滿足了企業合規需求,更建立了客戶對 AI 系統「不說謊、不洩密」的深度信任